Making Search in Imhex 2x faster
Overview
Project: ImHex (Open-source hex editor)
Function: searchStrings
File Path: ImHex/plugins/builtin/source/content/views/view_find.cpp
ImHex is a popular open-source hex editor used by developers to inspect and analyze binary data. This case study looks at how Functio — our AI-powered performance tool — identified and fixed bottlenecks in ImHex’s searchStrings function, a core routine for finding strings in large hex data sets.
Introduction
Functio is an AI tool that helps software engineers pinpoint, analyze, and resolve performance bottlenecks in code.
In this case, Functio was running on ImHex, focusing on the searchStrings function in view_find.cpp. This case study walks through:
1. What searchStrings does
2. How Functio set up and ran benchmarks
3. What we found in the performance analysis
4. The code changes and optimizations we applied
5. Performance results before and after
Functionality Description
The searchStrings function scans a chosen memory region byte-by-byte, looking for valid character sequences based on user-defined settings (SearchSettings::Strings).
It handles multiple encodings — ASCII, UTF-8, UTF-16LE, UTF-16BE — and even hybrid types like ASCII_UTF16BE by running multiple searches and combining the results.
Internally, it uses a prv::ProviderReader to pull bytes from the searchRegion and checks each one for validity (letters, numbers, punctuation, whitespace, underscores, and optionally line feeds). UTF-16 runs also validate that every other byte is zero, while UTF-8 checks ensure correct multibyte sequences.
When an invalid byte is found (or the end of the region is reached), the function checks if the current run meets the minimum length and null-termination requirements. If it does, it records the occurrence with its address, length, encoding type, and endianness, then resumes scanning.
The main loop of the function: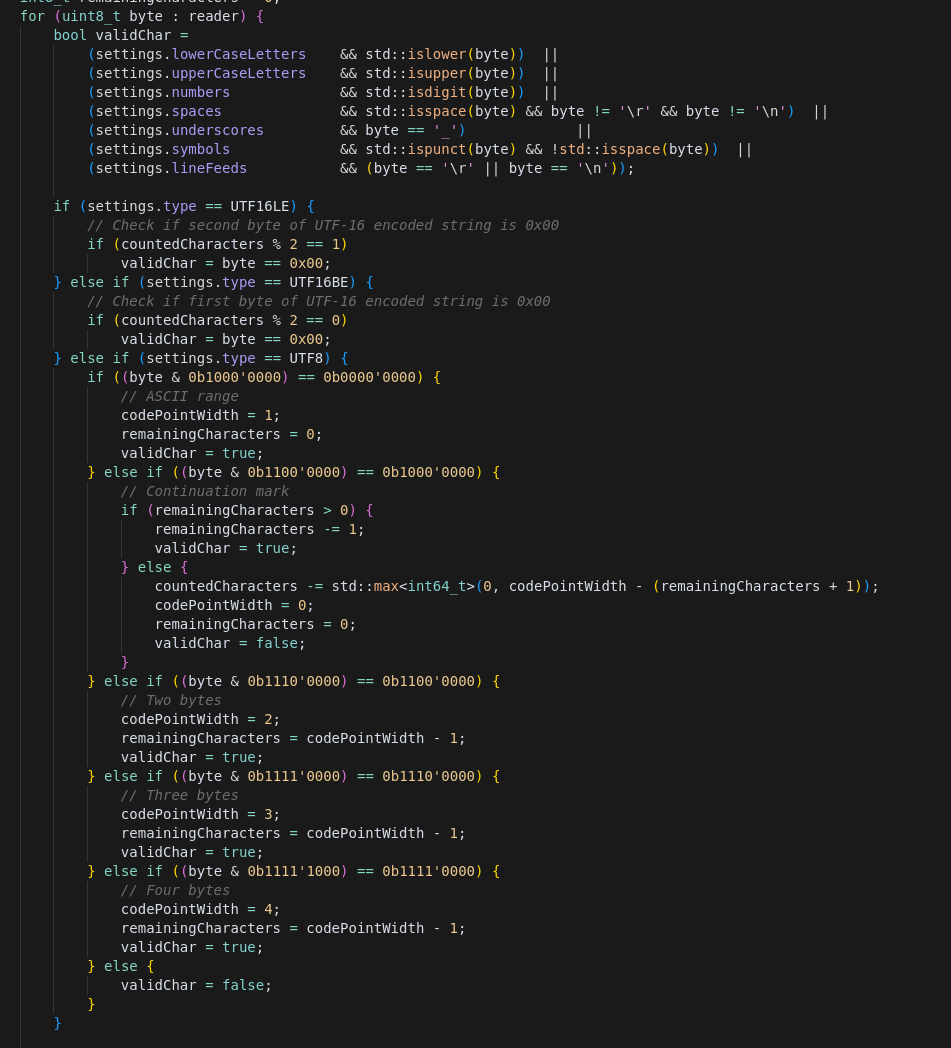
How Functio Approaches Optimization
Functio can work in two main ways:
1. Targeted function optimization – User provides the source file(s) containing the function to optimize. Functio extracts all dependencies, generates a standalone benchmark setup, and, if needed, creates mocks for missing functions. This setup includes a main function to drive the tests, using either your test inputs or ones Functio generates automatically.
2. Workflow-based optimization – User points Functio at a command, query, or workflow in a large project. Functio runs sampling profilers to find the slowest functions, then builds a standalone benchmark for them (just like in approach #1).
This Case
We used the workflow-based optimization, pointing Functio to ImHex, while it was running a string search.
functio imhex -d 5 - to record ImHex profiling data by PID for 5 seconds while search is running
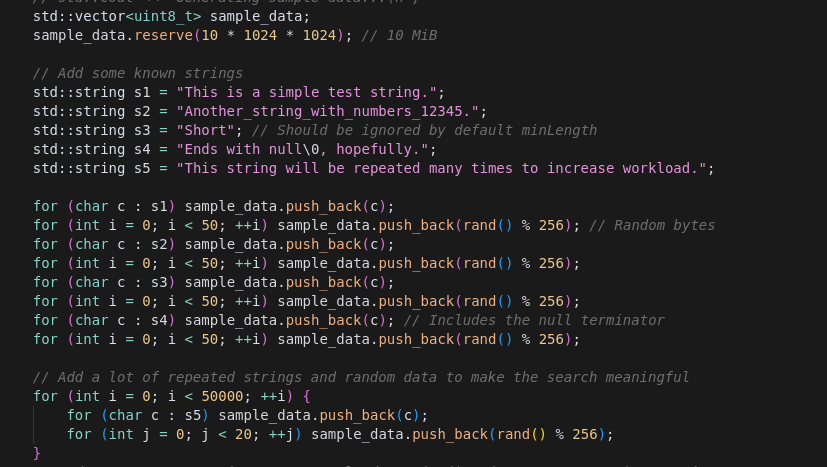
Test Inputs
Functio generated automatically the following test inputs to check the functionality and measure runtime of the original, and improved programs.
Analysis
When profiling searchStrings, Functio found two big issues:
1) Character classification overhead
Functions like std::islower, std::isupper, and std::isspace consumed a huge share of CPU time — 23.2%, 22.8%, and 8.7% respectively. Combined, these trivial checks took more time than the rest of the loop logic.
Best it can be visualized on a Flame graph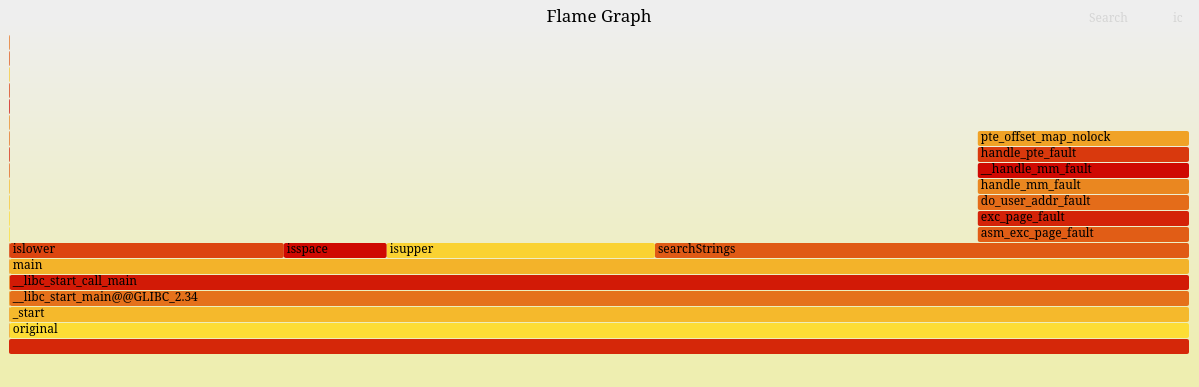
2) The main loop had a data dependency on the byte variable that blocked out-of-order execution. The CPU could not to the fullest utilize OOO exectuion, lowering IPC and overall throughput.
Optimizations Applied
Pre-computed Lookup Table
As the program goes byte by byte through the input stream, for each byte we check if it is lowercase/uppercase/number/space etc. In the current ImHex implementation it is done by checking each byte using 7 functions: std::islower(byte), std::isupper(byte), std::isdigit(byte), etc.
- Before:
- Every character validity check called multiple functions (islower, isupper, isdigit, etc.) on each byte.
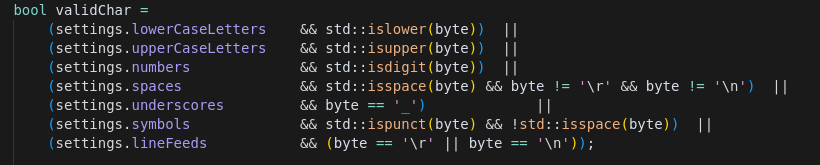
- After:
- Functio replaced those calls with a single lookup into a precomputed table that encodes all the validity rules. This removes repeated function-call overhead and branches.
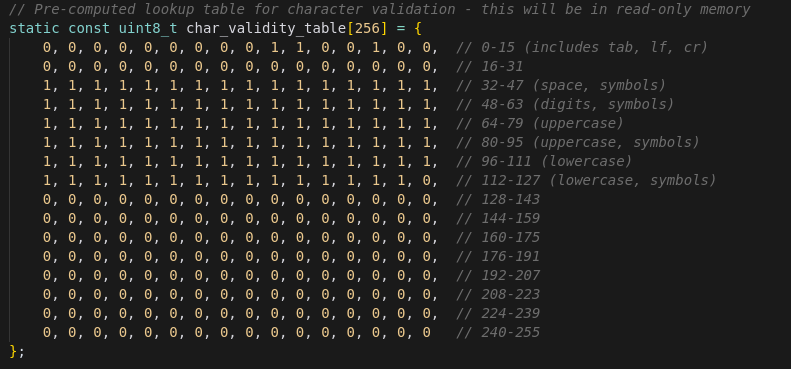
- Impact:
- Cycles spent per validity lookup measured through perf_event
- Original: ~131 cycles per single lookup (mean)
- Optimized: ~24 cycles per single lookup combined
Bulk Memory Loading
- Before:
- The reader processed one byte at a time inside the loop. This added per-byte overhead and made OOO execution harder.

- After:
- We read data in bulk into a buffer, allowing the compiler to auto-vectorize and reducing memory access overhead.

- This optimization opens an opportunity to break cross-iteration dependency chain, and reduces loop overhead
Dependency Chain Splitting
- Before:
- Sequential data dependency over variable byte created performance bottlenecks due to limited CPU parallelism. Due to the significant size of the loop CPU cannot deploy the next iteration until the very end of the previous one, under-utilizing the CPU.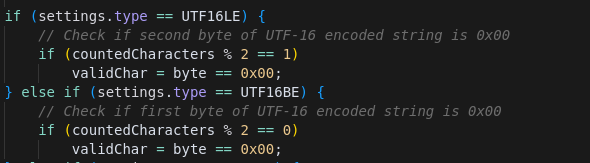
- After:
- Dependency chain split into four independent sub-chains. Functio found that 4 subchains yields optimal performance on our system.
- Enhanced CPU utilization through improved out-of-order execution capabilities, markedly boosting performance.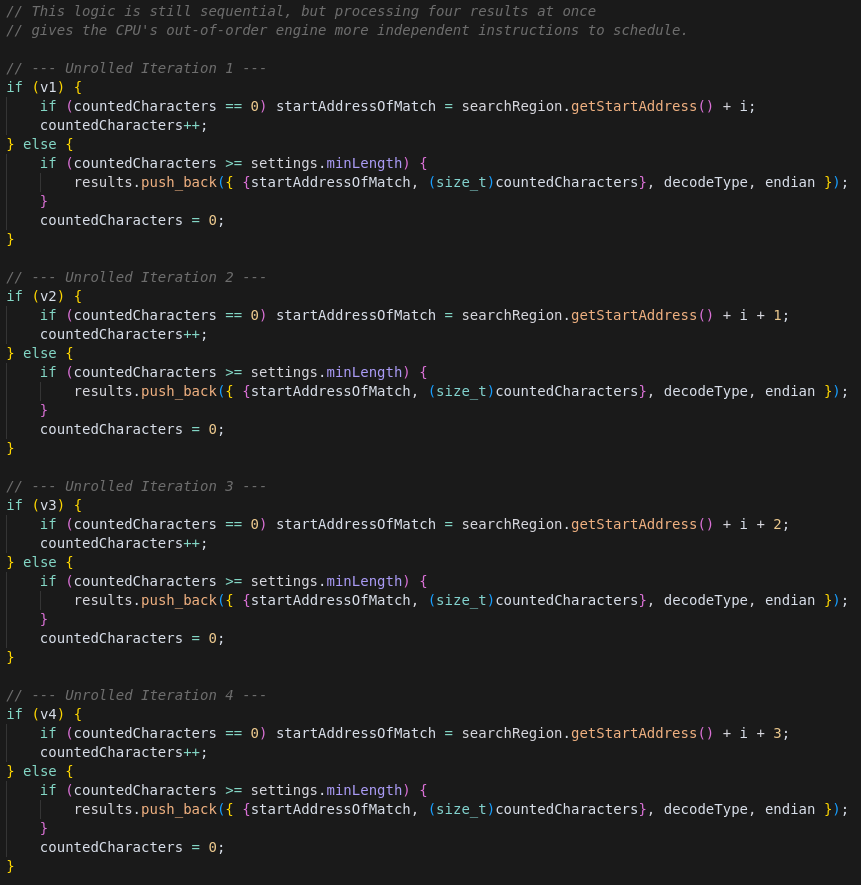
- Impact:
- Core-bound instruction count dropped from 43% to 26% in the Top-Down analysis.
Correctness
Functio automatically verified that the optimized version produced identical results to the original on all generated test inputs.
Results on the microbenchmark
Results of the original vs optimized benchmark setup were measured using perf stat.
Original Runtime: 0.1 s
Improved Runtime: 0.02 s
That’s a 5× speedup.
Full Results
After recompiling ImHex with the Functio patch, we run an end-to-end expieriment. We searched for all continious strings that are of 100 charachters in a sample hex file, and did the search 2 times: on the master implementation and the improved one.
Original Runtime: 14 s
Improved Runtime: 7 s
That’s a 2× end-to-end improvement.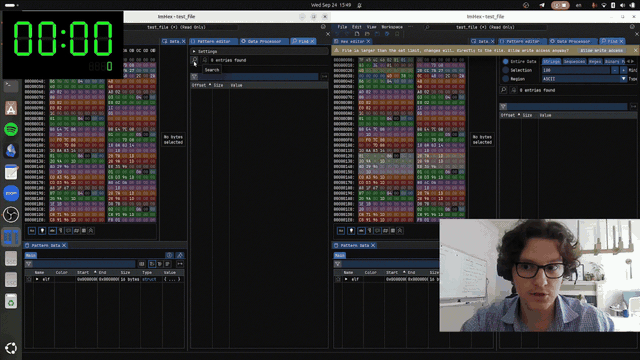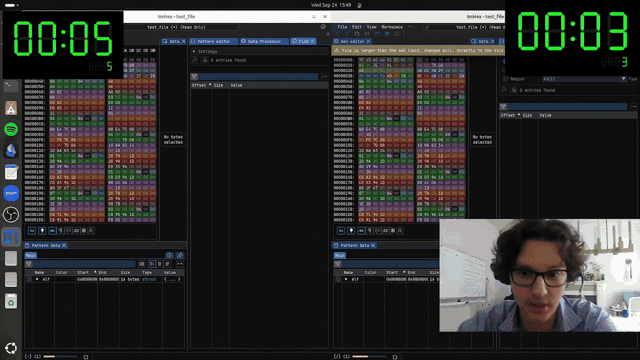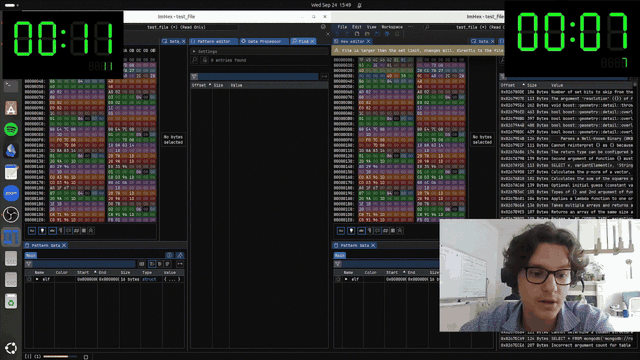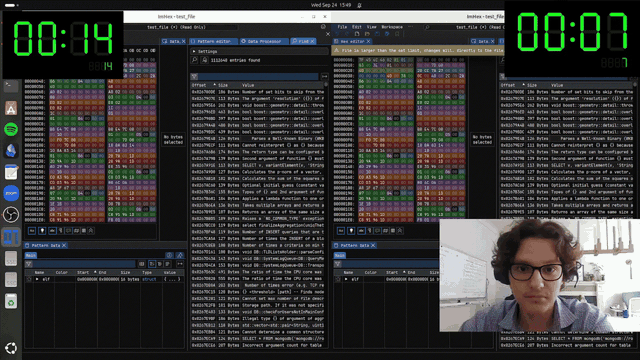
Full Recorded Demo
Conclusion
With a few focused changes — precomputed lookups, and breaking the dependency chain — Function made searchStrings5x faster, and Search as a whole 2x faster!
The code is a bit more complex now, but the performance gain is well worth it for heavy hex-data searches, making ImHex faster and more responsive for its users.
Need performance optimization?
Contact us to discuss how we can help optimize your performance-critical software.
Express Interest